
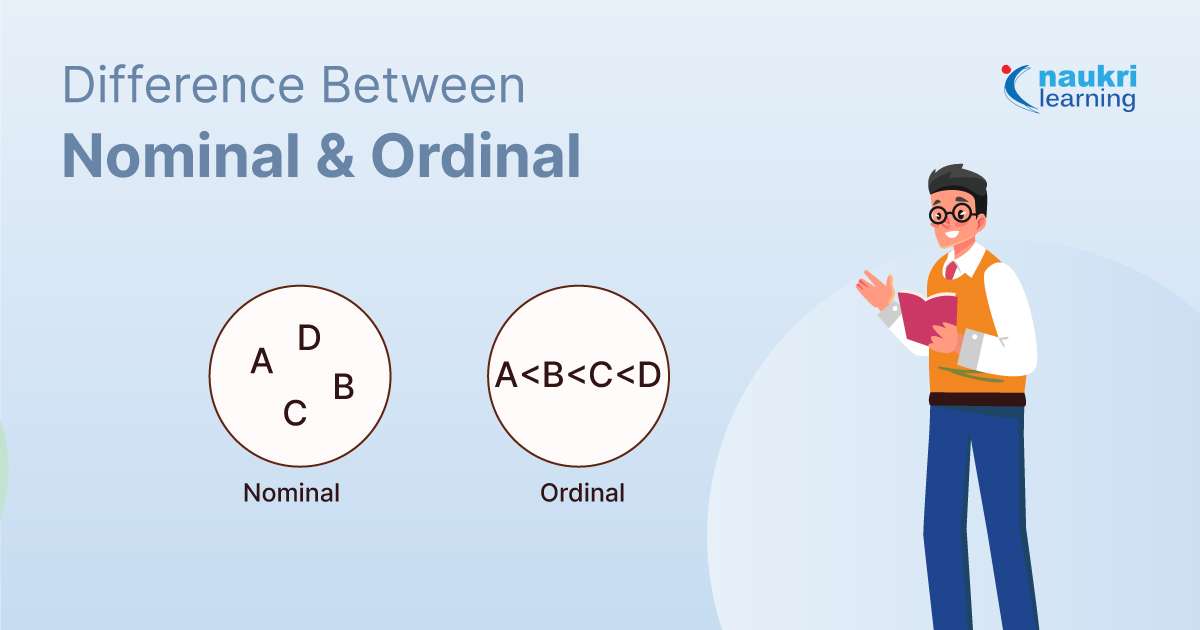
داده های اسمی و ترتیبی
61 Views
- دادههای اسمی نشاندهنده دستههایی بدون ترتیب ذاتی هستند (مثلاً رنگها، ژانرها)، در حالی که دادههای ترتیبی شامل دستههایی با ترتیب خاص و معنادار هستند (مثلاً رتبهبندی رضایت، سطح تحصیلات).
- شناسایی صحیح دادهها به عنوان اسمی یا ترتیبی برای انتخاب روشهای آماری مناسب (مانند شمارش یا میانه) و تکنیکهای تجسم (مانند نمودارهای میلهای یا نمودارهای دایرهای) بسیار مهم است.
- طبقهبندی صحیح نوع دادهها، تجزیه و تحلیل دقیق دادهها و تصمیمات تجاری آگاهانه را تضمین میکند، به خصوص هنگام خلاصه کردن اطلاعات یا ساخت داشبورد.
وقتی به دادهها فکر میکنید، چه چیزی به ذهنتان خطور میکند؟ اکثر مردم بلافاصله به دادههای عددی فکر میکنند – اعدادی که میتوانند اندازهگیری و کمّی شوند – اما این تنها بخشی از آن است.
اصطلاح دادهها به هر مجموعهای از اطلاعات یا اندازهگیریهایی اشاره دارد که میتوانند برای ارائه بینش یا تصمیمگیری تجزیه و تحلیل شوند. همه چیز از سن، قد و وزن ما گرفته تا رنگهای مورد علاقه، سرگرمیها و کارهای روزمره ما را میتوان اندازهگیری و در انواع مختلف دادهها طبقهبندی کرد.
هنگامی که بفهمیم چگونه این دادهها را طبقهبندی کنیم، میتوانیم تصمیمات آگاهانه بگیریم، روندها را تشخیص دهیم و جنبههای مختلف زندگی و رفتار را بهتر درک کنیم.
از بین انواع مختلف دادهها، دو نوع رایج، دادههای اسمی و دادههای ترتیبی هستند که اطلاعات را بر اساس ویژگیهای کیفی به دستههایی گروهبندی میکنند. (این به عنوان “دادههای طبقهبندیشده” شناخته میشود.) هر کدام هدف متفاوتی را دنبال میکنند و دانستن تفاوتها ضروری است – زیرا بر روشهای آماری مورد استفاده و دقت نتیجهگیری تأثیر میگذارند. به طور خلاصه:
دادههای اسمی بدون ترتیب طبقهبندی میشوند و فقط امکان تجزیه و تحلیل کیفی را فراهم میکنند.
دادههای ترتیبی یک رتبهبندی معنادار را ارائه میدهند و به تجزیه و تحلیل کمی متصل میشوند.
بیایید کمی عمیقتر به تفاوتهای بین دادههای اسمی و ترتیبی بپردازیم.
دادههای اسمی چیست؟
دادههای اسمی، اقلام یا متغیرها را بدون هیچ ترتیب یا رتبهبندی ذاتی، در گروههای مجزا دستهبندی میکنند. این دستهها صرفاً برچسبها یا نامهایی بدون هیچ مقدار کمی یا سلسله مراتبی هستند.
دادههای اسمی اغلب با کلمات یا نمادها برای تمایز بین دستهها نمایش داده میشوند. این دستهها متقابلاً منحصر به فرد هستند، به این معنی که یک فرد فقط میتواند در یک زمان در یک دسته قرار گیرد.
دادههای اسمی عموماً غیر عددی هستند و نمیتوان از آنها در محاسبات استفاده کرد.
ویژگیهای کلیدی داده های اسمی
- دستهها متقابلاً منحصر به فرد هستند و نمیتوانند همپوشانی داشته باشند.
- هیچ ترتیب یا رتبهبندی ذاتی بین دستهها وجود ندارد.
- عملیات ریاضی مانند جمع یا ضرب بیمعنی هستند.
- مد تنها راه برای یافتن رایجترین دسته است.
نمونههایی از دادههای اسمی
- جنسیت: مرد، زن، سایر
- وضعیت تأهل: مجرد، متأهل، مطلقه، بیوه، سایر
- رنگ مورد علاقه: قرمز، آبی، بنفش، زرد و غیره.
- انواع حیوانات خانگی: گربه، سگ، ماهی، پرنده و غیره.
- گروه خونی: A، B، AB، O
- دادههای اسمی در سناریوهای دنیای واقعی
- بازاریابی: تقسیمبندی مشتریان بر اساس محصولات مورد علاقه.
- بهداشت و درمان: دستهبندی بیماران بر اساس گروه خونی.
- آموزش: طبقهبندی دانشآموزان بر اساس فعالیتهای فوق برنامه.
معیارها و تکنیکهای مناسب داده های اسمی
از آنجا که دادههای اسمی دستهبندی هستند، دامنه معیارهای آماری قابل اجرا محدود است. از مد معمولاً برای شناسایی رایجترین دسته استفاده میشود. توزیعهای فراوانی میتوانند خلاصه کنند که هر دسته چند بار اتفاق میافتد.
تکنیکهای تجسم داده های اسمی عبارتند از:
نمودارهای میلهای برای نمایش فراوانی دستهها در دادههای اسمی ایدهآل هستند. هر میله نشاندهنده یک دسته است و ارتفاع آن با فراوانی دسته مطابقت دارد.
نمودارهای دایرهای برای نشان دادن نسبت هر دسته در کل مجموعه دادهها استفاده میشوند. هر برش از دایره نشاندهنده یک دسته است و اندازه برش متناسب با فراوانی آن دسته است.
دادههای ترتیبی چیست؟
دادههای ترتیبی، اقلام یا متغیرها را در گروههای متمایز با ترتیب یا رتبهبندی معنادار دستهبندی میکنند. اگرچه دستهها دارای ترتیب طبیعی هستند، اما تفاوت بین آنها لزوماً برابر یا قابل اندازهگیری نیست.
دادههای ترتیبی اغلب با اعداد یا کلماتی نمایش داده میشوند که رتبه هر دسته را نشان میدهند.
دادههای ترتیبی: ویژگیهای کلیدی
- دستهبندیها ترتیب یا رتبهبندی مشخصی دارند
- تفاوتهای بین دستهها ممکن است برابر یا قابل اندازهگیری نباشند
- عملیات ریاضی مانند جمع و ضرب معنادار نیستند، اما مقایسههایی مانند بزرگتر یا کوچکتر بودن امکانپذیر است.
- میانه و صدکها برای یافتن میانه و مقایسه رتبهبندیها مناسب هستند.
مثالهای داده های ترتیبی
- سطح تحصیلات (دبیرستان، لیسانس، فوق لیسانس، دکترا)
- رتبهبندی رضایت مشتری (بسیار ناراضی، ناراضی، خنثی، راضی، بسیار راضی)
- سطح درآمد (پایین، متوسط، بالا)
- پاسخهای مقیاس لیکرت (کاملاً مخالف، مخالف، خنثی، موافق، کاملاً موافق)
- رتبهبندی فیلم (یک ستاره، دو ستاره، سه ستاره، چهار ستاره، پنج ستاره)
- دادههای ترتیبی در سناریوهای دنیای واقعی
- خدمات مشتری: تجزیه و تحلیل رتبهبندی رضایت برای بهبود خدمات.
- منابع انسانی: رتبهبندی سطوح عملکرد کارکنان.
- تحقیقات بازار: ارزیابی ترجیحات مصرفکننده در یک مقیاس.
معیارها و تکنیکهای مناسب داده های ترتیبی
با توجه به ماهیت مرتب دادههای ترتیبی، برخی از تکنیکها و معیارهای آماری به طور خاص مرتبط هستند. میانه، نقطه مرکزی مجموعه دادهها را مشخص میکند و معیاری از گرایش مرکزی را ارائه میدهد. صدکها مجموعه دادهها را به ۱۰۰ قسمت مساوی تقسیم میکنند و به شما امکان میدهند رتبهبندیهای موقعیتی را مقایسه کنید.
تکنیکهای تجسم داده های ترتیبی عبارتند از:
نمودارهای میلهای: مشابه دادههای اسمی، نمودارهای میلهای برای دادههای ترتیبی مفید هستند تا فراوانی هر دسته را نشان دهند. میلهها بر اساس رتبهبندی ذاتی دستهها مرتب شدهاند.
نمودارهای نقطهای: این نمودارها میتوانند توزیع نقاط داده منفرد را در دستهها نشان دهند و پراکندگی و خوشهبندی را در گروههای رتبهبندی شده برجسته کنند.
نمودارهای میلهای مرتب یا ترتیب دار: نمودارهای میلهای مرتب، بهبود یافته نمودار میلهای استاندارد، دستهها را به ترتیب متوالی نمایش میدهند و نمایش بصری از رتبهبندی ارائه میدهند.
تفاوتهای کلیدی: دادههای اسمی در مقابل دادههای ترتیبی
علیرغم شباهتهایشان در شکلگیری دادههای دستهبندیشده، دادههای اسمی و ترتیبی اساساً در نحوه برخورد و تحلیل آماری با یکدیگر متفاوت هستند. در اینجا برخی از تفاوتهای کلیدی بین دادههای اسمی و ترتیبی آورده شده است:
ترتیب و رتبهبندی
- دادههای اسمی: فاقد هرگونه ترتیب یا رتبهبندی ذاتی در بین دستهها (مثلاً انواع حیوانات خانگی) هستند. هر دسته بدون هیچ موقعیت ضمنی نسبت به دستههای دیگر، به تنهایی قرار میگیرد.
- دادههای ترتیبی: دارای ترتیب یا رتبهبندی واضحی در بین دستهها (مثلاً سطح تحصیلات) هستند، اگرچه فواصل بین دستهها لزوماً برابر یا قابل اندازهگیری نیستند.
عملیات ریاضی
- دادههای اسمی: عملیات ریاضی مانند جمع، تفریق، ضرب و تقسیم برای دادههای اسمی بیمعنی هستند. تمرکز اصلی بر شناسایی و شمارش دستهها است.
- دادههای ترتیبی: در حالی که جمع و ضرب نامناسب هستند، مقایسههایی مانند بزرگتر از، کوچکتر از یا مساوی امکانپذیر است. ماهیت ترتیبی امکان تعیین میانه و صدکها را فراهم میکند.
یافتن میانگین
- دادههای اسمی: مد، که دستهبندی با بیشترین فراوانی را شناسایی میکند، تنها معیار گرایش مرکزی قابل استفاده برای دادههای اسمی است.
- دادههای ترتیبی: هم میانه و هم مد معیارهای مناسبی برای گرایش مرکزی هستند. میانه، بینشی در مورد مقدار مرکزی یا موقعیت دادهها در صورت مرتب شدن ارائه میدهد.
تکنیکهای تجسم
- دادههای اسمی: بهترین روش برای نمایش، استفاده از نمودارهای میلهای و نمودارهای دایرهای است که فراوانی یا نسبت هر دستهبندی را نشان میدهند.
- دادههای ترتیبی: در حالی که میتوان از نمودارهای میلهای استفاده کرد، باید ترتیب ذاتی دستهبندیها را رعایت کرد. نمودارهای میلهای مرتب و نمودارهای نقطهای نیز در نشان دادن ماهیت رتبهبندی دادهها مؤثر هستند.
تحلیل دادهها
- دادههای اسمی: بر فراوانیها و نسبتها تمرکز دارد که اغلب از طریق جداول و نمودارهای پایه خلاصه میشوند. تحلیل شامل شمارش و مقایسه اندازههای دستهبندیهای مختلف است.
- دادههای ترتیبی: از تکنیکهای تحلیلی پیچیدهتری که ترتیب دستهبندیها را در نظر میگیرند، مانند تقسیم میانه، رتبههای درصدی و آزمونهای آماری ناپارامتری مانند آزمون U مان-ویتنی پشتیبانی میکند. درک این تمایزات برای انتخاب روشها و مصورسازیهای آماری مناسب هنگام کار با دادههای طبقهبندیشده بسیار مهم است. بهکارگیری تکنیکهای صحیح تضمین میکند که تجزیه و تحلیل، ماهیت دادهها را به طور دقیق منعکس میکند و نتایج معناداری به دست میدهد.
اهمیت طبقهبندی صحیح
طبقهبندی صحیح دادهها در تجزیه و تحلیل دادهها بسیار مهم است زیرا مستقیماً بر انتخاب روشهای آماری و تفسیر نتایج تأثیر میگذارد. طبقهبندی نادرست دادهها میتواند منجر به فرضیات نادرست و نتیجهگیریهای ناقص شود.
یک نظرسنجی رضایت مشتری را در نظر بگیرید که در آن پاسخدهندگان تجربه خود را در مقیاسی از ۱ (بسیار ناراضی) تا ۵ (بسیار راضی) ارزیابی میکنند. این مقیاس رتبهبندی، دادههای ترتیبی را نشان میدهد. اگر به عنوان دادههای اسمی در نظر گرفته شود، ترتیب یا رتبهبندی نادیده گرفته میشود و منجر به نمایشهای نادرست و روندهای از دست رفته میشود.
به عنوان مثال، محاسبه مد به جای میانه، ترتیب سطوح رضایت را نشان نمیدهد و به طور بالقوه استراتژیهای تجاری را نادرست میکند.
در نظر گرفتن دادههای ترتیبی به عنوان اسمی میتواند منجر به از دست دادن اطلاعات ارزشمند در مورد ترتیب دستهها شود، در حالی که در نظر گرفتن دادههای اسمی به عنوان ترتیبی میتواند با دلالت بر یک ترتیب ناموجود، سوگیری ایجاد کند.
خلاصهسازی دادههای اسمی در مقابل دادههای ترتیبی
درک تمایزات بین دادههای اسمی و ترتیبی برای تجزیه و تحلیل دقیق دادهها ضروری است.
شناخت این تفاوتها، کاربرد صحیح تکنیکهای آماری را تضمین میکند و یکپارچگی تحلیل شما را حفظ میکند. با این حال، طبقهبندی نادرست این نوع دادهها میتواند منجر به بینشهای نامعتبر و تصمیمات ناقص شود. با شناسایی و تجزیه و تحلیل صحیح دادههای اسمی و ترتیبی، میتوانید نتیجهگیریهای دقیقتر و معناداری از مجموعه دادههای خود به دست آورید.
مطالب مرتبط مفید

پاسخگوی سوالات و نظرات شما هستیم